有人的地方就有江湖。武侠江湖中有侠客、剑客;安全江湖内有黑客、红客、极客……不会代码、没有神技的小编靠着娴熟的叨法,自封了一个名号——
第10叨
什么是“安全基线引擎”
猫大家都认识吧!
那我们不妨来回答一下这个陌生而又熟悉的问题,请从下图中找出不一样的猫。(不熟悉的读者可以点击图片或标题回看《灵魂拷问:如何把网络攻击从数百万合法行为里抓出来?》)

细心的朋友可能很快就发现,第二排最后一只猫没有眼睛,用时都不到一秒。
但问题来了,毕竟这只是3x8的矩阵,如果这里有几万只甚至几百万只猫呢?怎么才能找到不一样的那只?

想要解决这个问题,首先得有一个标准,换个高大上的词来说就是——基线。
如果觉得猫不够熟悉,那换个话题,什么人才不是正常人?
有人肯定会说,长了三只眼睛的肯定不是正常人,应该是二郎神。此话有理,但恐怕这个世界上99.99%的人,一辈子都没见过谁长三只眼。如果用这个或者一组类似的标准来判断,全世界怕是没几个不正常的。
但有一类人肯定对这个问题很有感觉,他们一项很重要的工作就是告诉别人你是不是有病,这类人叫做医生。
关于如何判断就诊人员是否患有某些疾病,很多国家和地区的卫生组织都发布了自己的标准:比如在中国,舒张压大于等于90或者收缩压大于等于140(单位:毫米汞柱)就被认为是高血压,对脏器会产生明显危害;非同日两次空腹血尿酸水平,男性大于416.5umol/L,女性大于357umol/L即可诊断高尿酸血症,痛风概率就非常大了。
我们可以把所有的这些标准给串起来,这条线就叫做生命健康的安全基线。凡是在超出了安全基线的,或多或少都有点“毛病”。
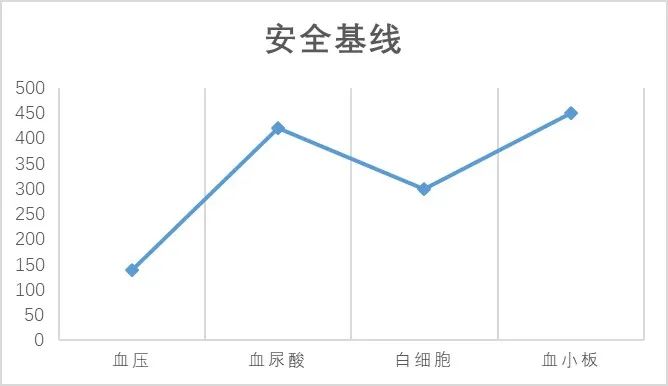
那么问题来了,安全基线到底是怎么来的呢?
有一点可以肯定,这是长期的诊疗实践再加上科学研究得出来的结果。所幸的是,人与人之间的差距并不算大。无论是东方人还是西方人,血压长期180都是有可能猝死的;无论男人女人,BMI超过30,怎么着也不会是个瘦子;无论大人小孩,体温39度都不会舒服。但很多时候并不是这样,尤其是信息系统。某国内知名电商网站单日访客量破亿稀松平常,但大多数企业官网一年都很难达到,要是达到了,作为网管就得考虑是不是被攻击而出现了有大量的恶意访问。这就比如你在闹市区里开120公里/时和在跨省高速上开120公里/时,交警对你的态度肯定不一样。
给每个信息系统画一条安全基线,是奇安信态势感知与安全运营平台(NGSOC)基线引擎最重要的任务,对于检查信息系统是否“有病”至关重要。
这就像规定了一条跑道,信息系统一旦跑过线就犯规了。
公交车老司机
和田径赛场上的跑道不同,安全基线并不是笔直或者椭圆形的那么规则,设计起来还颇有点难度。
设计基线的方法大概有以下几种。
假设你是一名公交车老司机,疫情期间你发现经常有学生党、上班族因赶时间而忘记戴口罩。出于好心,你决定发起“口罩工程”,自掏腰包在车上准备一些口罩,免费给那些忘记的人使用,免得他们还得再跑回去取,耽误行程。但口罩数量毕竟有限,为了让真正的乘客使用,你制定了一个规则:乘车才能使用,不乘车不可以。刚开始一切正常。但很快口罩就从最开始的平均消耗一两个,变成了后来的一天能送出去十多个。这让老司机颇为不解,怎么记性不好的人越来越多了。经过一段时间的仔细观察,老司机发现原来是有人故意不戴口罩就等着上车拿。由于很难确定到底谁是故意的,于是老司机决定每天限量供应五个。
这就是统计类安全基线,它主要来自于长期的数据统计和机器学习。一旦一段时间内的平均数值要明显高于或者低于统计结果,就可能出现问题了。
限量规则的实施,使得那些投机不戴口罩的数量随之大幅减少,大家都很担心自己成为第六个或者之后的人。
但很快老司机又发现了一个问题,下午要口罩的人明显增多。
通常而言,忘带口罩的人多出现在早晨8:00-9:00上班或者上学高峰,下午则几乎没有。几经调查老司机发现,由于免费口罩需求量减少,到下午仍有剩余,因此开始出现了下午来“免费蹭口罩”的人群。于是老司机又决定,非早高峰时间限量两个。
这就产生了序列类安全基线,它有明显的时间先后顺序或者周期性。一旦事件发生明显偏离了预定的先后顺序或者违背了周期规律,则会判定会异常。
一段时间后,老司机逐渐和那些忘带口罩的人混了个脸熟。他发现,经常忘戴口罩的总是那么几个。尽管一个口罩值不了多少钱,但为了帮助这些经常忘记戴口罩的人养成好习惯,老司机决定凡是在他脑袋里挂了号的人,以后再领口罩时,就象征性的收五毛钱口罩费,让他们在出门前想想今天是不是戴口罩了。
老司机人工学习(机器学习)除了忘记带口罩人的特点并完成聚类,就产生了机器学习类安全基线。
经过老司机几个月的实践,口罩工程基本走上了正轨。
在这个过程中,他使用的统计类安全基线、序列类安全基线和机器学习类安全基线,就是网络安全检测与分析中使用最为广泛的三类安全基线。
实时计算
相比之下,网络安全分析要复杂的多。
首先需要快速的响应。说简单点,安全检测其实就是把发生的事件与安全基线进行比对,找出异常。由于安全事件经常是突发的,而且发现和处理的速度越快损失就会越低,这就意味着需要用一种简单快速的方式,快速生成安全基线,并与突发的安全事件进行比对。反观老司机可以无所谓,无非就是多发几个口罩。
其次是场景定制。作为学生党或者上班族,每天上班的时间、线路都相对比较固定,对于老司机而言大家都差不多。但安全分析不同,它的对象有数据、时间、流量、文件甚至还有很多安全领域独有的一些需求,所以定制开发很常见。
第三是资源受限。没有谁的资源是无穷无尽的,在预算有限的情况下,计算、存储、带宽这些资源要优先保证组织自身业务的正常开展,别像某一码通隔三差五就被搞宕机了,被上级有关部门要求扩容。因此,网络安全分析要在确保性能的基础上,尽可能占用更少的资源。强如老司机,虽说一天也能拉上千个乘客,但每天最多就发五个口罩。
基于上述特点,NGSOC安全基线引擎就必须具备强大的实时计算能力,说白了就是左边输入数据,右边就能输出结果,同时还不能占用太多资源,支持定制化开发。
这里解释一个概念。
如果按照时效来分类,计算类型主要包括实时计算和延迟计算。所谓的延迟计算就是指在某一时间点,对过去的某一段时间内发生的事件、产生的数据进行计算。老司机的做法就是一种典型的延迟计算,过一段时间会对之前的口罩发放情况进行总结。
实时计算则是指能够在事件发生的同时,快速统计并输出检测结果。对于IT系统而言,事件会持续发生,比如防火墙会不停的过滤数据包,公司的办公系统会不停地被访问,因此事件是无穷无尽的。这就像地铁安检系统,只要乘客经过安检系统,实时的影像就已经在电脑上显示出来了。如果地铁安检也搞延迟计计算那一套,整个地铁站还不堵成一锅粥了。
那么有没有什么技术可以实现这些要求呢?
“还记得在2018年的时候,我们比较了很多技术栈,最终选择了ApacheFlink作为实时计算框架。基于这个开源框架,我们设计出了国内首款分布式关联分析引擎Sabre和安全基线引擎。”
说这句话的人是奇安信NGSOC基线引擎负责人覃永靖,一名深耕大数据安全检测领域多年的高级技术专家。
毫不夸张地说,Flink是时下最流行的数据计算框架之一。
事实上,Flink最开始并不叫Flink,它的前身是Stratosphere,中文翻译是平流层,位于离地表10公里至50公里的高度。当然最开始也不属于Apache,而是由一群技术宅在开发完成后,于2014年捐献给Apache基金会的。
说到这儿,或许Flink的诞生与平流层通信有着密切的关系。与卫星通信相比,平流层通信的极低延迟正是开发者追求的目标。
Flink最重要的特点是允许以数据并行和流水线方式执行任意流数据程序,并且具备高吞吐低延迟的能力。正是这个特点,Flink让实时计算从“奢侈品”变成了“日用品”。想象一下大量工业制品在多条流水线上“奔跑”的样子,而Flink就是在数据流水线上的自动化生产机器。
安全基线引擎
不过直接把Flink拿过来,离覃永靖脑海中的实时基线引擎还差的很远。
至于差在哪,先看基线引擎最常见的三个实战案例。
第一种是数据库管理员(DBA)账户登录异常,基线引擎可以学习DBA账户的登录习惯,比如当账户登录位置偏离了常见的登录位置时,就反馈为异常登录,账户有可能被盗用。
第二种是邮件异常,基线引擎可以学习某一个用户或者是整个组织的收发邮件行为,例如当用户邮件数量或者附件数量远远超出历史学习水平,则邮件系统可能正被控制对外发送大量垃圾邮件。这个时候组织可以用过设置邮件发送数量上限来达到限制目的。
第三种是VPN账户异常,基线引擎可以学习用户登录VPN服务的次数和登录VPN后的行为(比如访问哪些系统、做了什么操作等等),一旦检测到用户登录行为和学习结果有出入,例如在敏感时间访问了某些敏感数据,则可能VPN账户已被入侵或者出现了内鬼。
这三个实战案例首先讲述了一个事实:在安全检测的场景中,Flink框架上可能同时运行着大量的安全基线。然而,它并没有针对大规模语义和规则进行优化,直接拿过来用可能根本无法同时跑起来这么多基线,大多数情况下上超过100条SQL语句系统就得“罢工了”。
这显然无法满足安全分析的需求。更无奈的是,Flink的使用和调优门槛非常高。
这里再普及一个知识。
基线的生成分为三个阶段。
第一阶段是学习阶段,在这一段时间内基线引擎的任务就是不断学习数据;在学习阶段结束后,系统往往会设置一段等待时间,在等待的时间里,基线不再学习新的数据,可以投入安全检测也可以不投入;等待时间结束后,基线就会全面投入到安全检测中,直到这条基线被删除或者失效。
需要注意的是,从基线引擎学习完毕到基线正式投入使用,这两个阶段之间还需要经过一个编译的过程。打个比方,部队集结完毕之后直接拉上战场肯定不行的,上级首长得一点点把任务布置下来,再由分队主官把任务分解给每一名士兵,否则还不全都乱套了。
Flink难就难在这里。
这个过程难到什么程度呢?大概类比一下,差不多和电脑小白用户抛弃Windows桌面操作系统去使用DOS命令差不多。你想执行个什么操作光靠鼠标还不行,得编写好长一段代码。但很多时候,用户根本就没有太多开发经验,只会启用规则、停用规则、看报警之类的。
“这肯定不行,我们的初衷应该是用户想象中该怎么用,系统就该怎么用。”覃永靖说到。
所以基线引擎引入了一个特殊的组件DSL,全称DomainSpecificLanguage,中文翻译成领域专用语言。这里的DSL主要是相对于通用机器语言如Python、C++等,特地用于安全分析领域。很明显,DSL就是专门给安全分析人员用的。DSL提供了一个非常友好的使用界面,能够以极短的代码来表达复杂的语义,并且支持的语义数量十分丰富。语义下发后,编译器能够快速编译成一条规则,从而首先解决了简单易用的问题。除此之外,DSL还很大程度上解决了性能的问题。DSL编译器在给基线布置任务的同时,会对公共表达式也就是任务进行优化,从而降低资源占用。比如有500个分析场景,这500个分析场景很可能会使用和相同的计算公式,还要同时处理大量的威胁情报数据,此时就需要支持对公共表达式的优化,同样的任务不用为每一条基线都布置一次。这样一来,在有限的资源下,引擎就可以同时运行更多数量的安全基线。
“矫情的”基线
基线运行起来也不是就万事大吉了。作为指挥官,除了要时刻关注检测结果,还要关注士兵的作战状态。
因此基线引擎需要重点关注两个方面:第一是基线的资源消耗情况,第二是基线自身还能不能满足安全检测的需要。
首先,基线引擎的运行要保证稳定性,保证稳定性的根本就在于资源。俗话说兵马未动粮草先行,如果说基线是作战的士兵,那么CPU、内存、带宽这些资源就是粮食弹药了。粮食弹药不足,军心必乱。当年袁绍七十万大军,就因屯粮的乌巢被袭占,而在官渡之战中输给了兵力只有其十分之一的曹操。
假如基线引擎同时运行了几十上百个基线,如果发现某一条基线的资源占用大大超出预估,那么就需要对它采取保护性措施,把它隔离出来或者干脆删除这条基线,防止它影响其他基线的运行。
覃永靖解释说,我们的基线引擎提供了资源保护机制,会根据安全检测的重要性顺序,为用户提供优先级管理,如果基线的优先级本身比较低,但是却占用大量的资源,就应该适当削减资源分配甚至停用。
其次,基线本身并不是一成不变的,业务系统的变化必然导致基线也随之需要更改。举个例子,有安全研究表明,近些年来人们的平均体温在逐年降低,若干年后如果再用大于等于37.3℃这个标准来判断是否发热可能就不合适了,基线标准也会适时调整。但基线在运行过程中要实现在线编辑,并不是一件非常容易的事情,搞不好就容易出错,出错的点就在于如何把修改成功的基线再发送到对应的节点上去。很多人都看过类似的剧情:一名士兵在受伤后被送到战地医院救治,出院后就找不到自己的队伍了。
因此,基线引擎设计了一套“路由机制”,它支持全局基线更新流图,能够在基线更改之后实现精确基线数据分发。
作为奇安信NGSOC的核心能力,关联分析引擎、安全基线引擎提供的实时安全分析能力,不知道打败了多少丧心病狂的黑客。
还有值得一提的是,这个引擎并不是NGSOC独享的,它目前正服务于奇安信大部分大数据产品,比如大数据与安全运营平台、态势感知、EDR、云安全、工业互联网安全、智能安全等,并随着这些产品服务了不计其数的客户。
从一到几百台集群规模,从几百到上百万EPS的安全事件,在成千上万的实战中,它见证了光。
PS:2022年1月8-9日,FlinkForwardAsia2021线上举办,以上内容根据覃永靖在会上分享的《如何设计信息安全领域的实时安全基线引擎》议题整理。

 立即拨打
立即拨打










 京公网安备11000002002064号
京公网安备11000002002064号